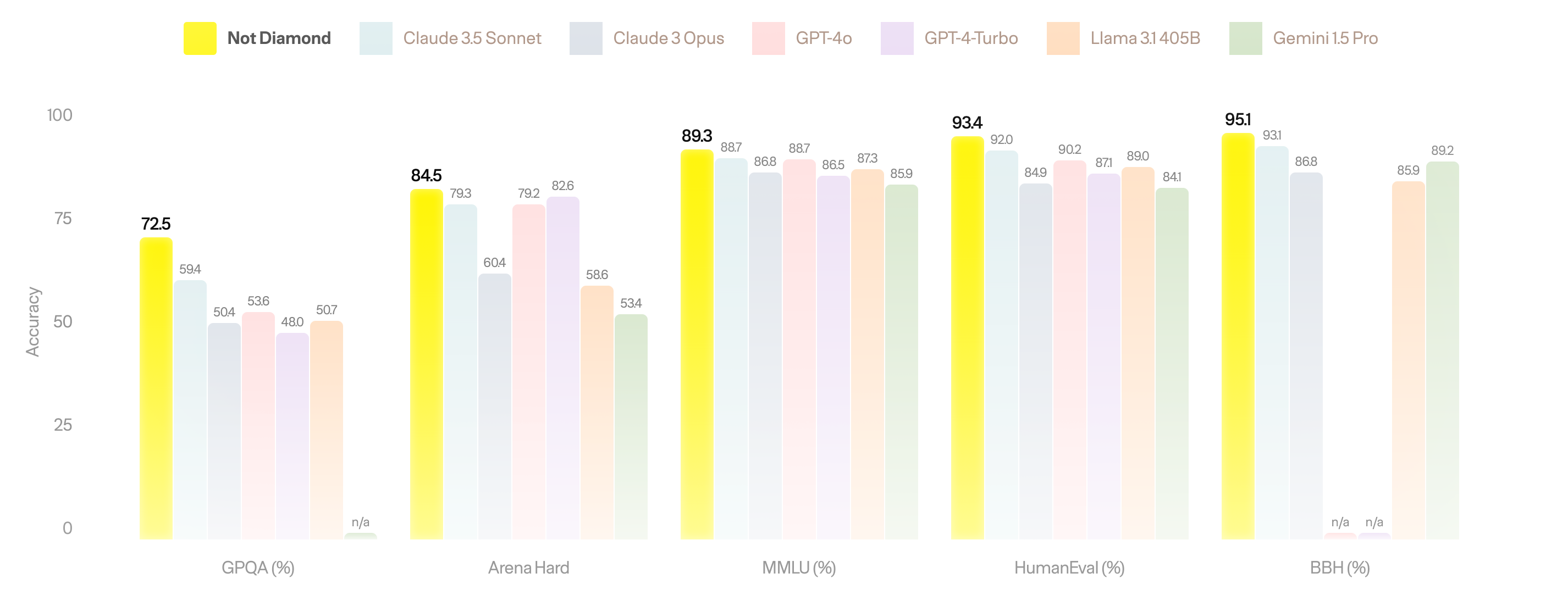
Benchmark performance
Not Diamond outperforms every foundation model on major benchmarks:
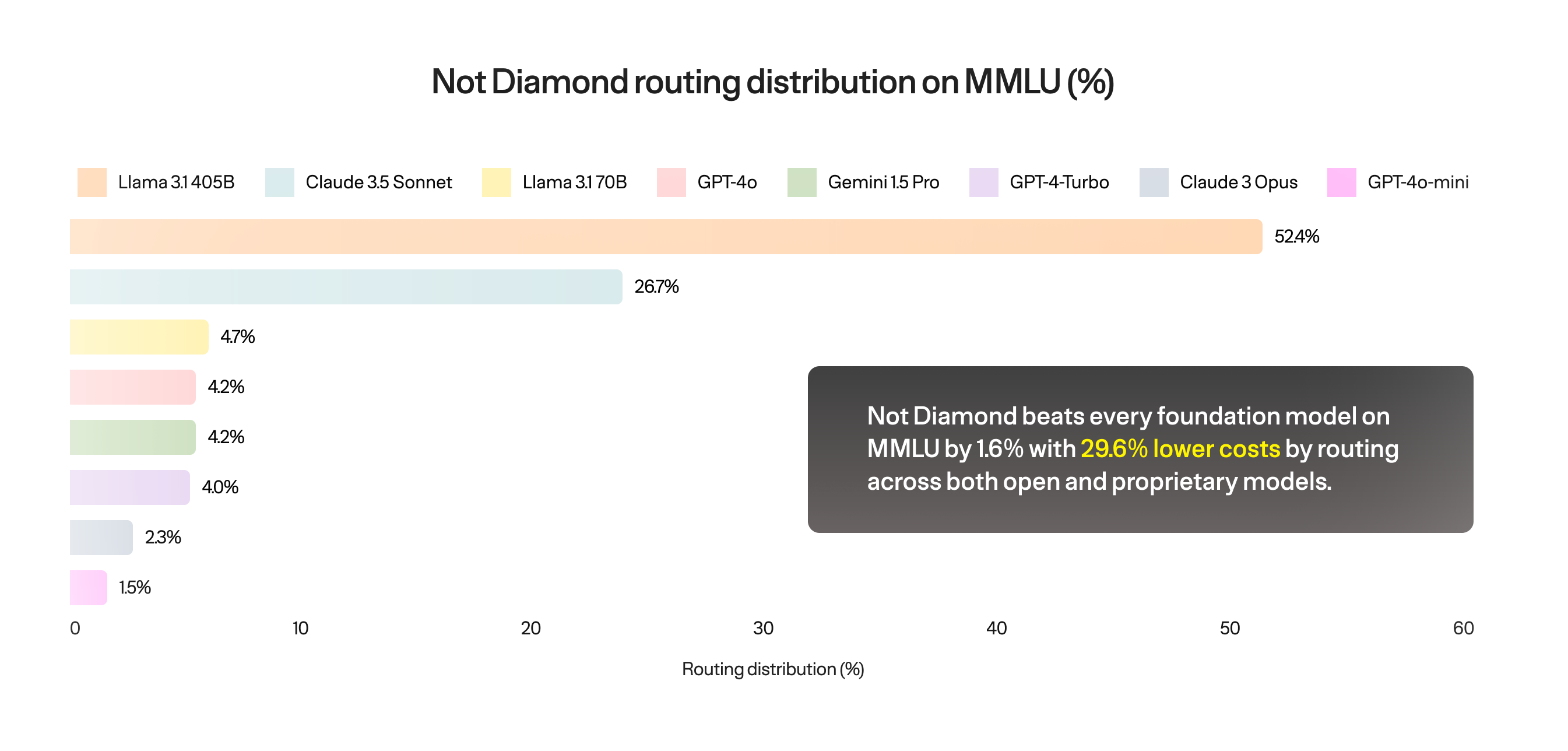
Not only does routing achieve state of the art performance, it does so at a significantly lower cost. For example, on MMLU Not Diamond beats GPT-4o while also lowering cost by nearly 30%. Here’s the routing distribution by model:
 We achieve these results by training custom routers optimized for each benchmark dataset. Datasets are split between training and testing, and we report on the test set performance. You can validate these results yourself by using Not Diamond's custom router training interface.
We achieve these results by training custom routers optimized for each benchmark dataset. Datasets are split between training and testing, and we report on the test set performance. You can validate these results yourself by using Not Diamond's custom router training interface.
We understand that benchmarks are weakly correlated with real-world performance. However, they powerfully illustrate how for any distribution of data—including some of the most challenging known to exist—Not Diamond will learn to route between LLMs to outperform each of them individually.
Updated 7 months ago